- tags
- Reinforcement learning
- source
- (Pathak et al. 2017)
DONE Summary
This paper presents a curiosity-based method for training RL agents. These agents are given a reward \(r_t\) which is the sum of an intrinsic and an extrinsic rewards. The latter is mostly (if not always) 0, while the former is constructed progressively during exploration by an Intrisic Curiosity Module (ICM).
The module is illustrated below (figure from the paper).
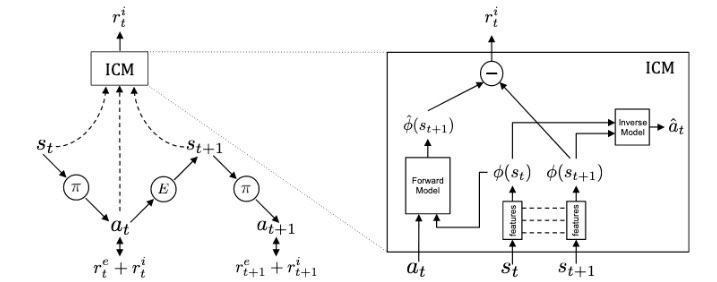
The left part of the figure represents a standard RL setup where actions are taken according to a policy and they affect the state of the agent.
The ICM module is a constantly evolving reward function composed of 3 sub-modules:
- A feature encoder \(\phi\) which encodes the states into feature vectors.
- A forward model which tries to predict the encoded next states \(\phi(s_{t + 1})\) from the current encoded state and action taken.
- An inverse model that predicts the action taken from both the previous state and next state.
The intrinsic reward is the scaled squared difference between estimated \(\hat{\phi}(s_{t + 1})\) and \(\phi(s_{t + 1})\). This setup rewards exploration because large errors in the prediction of the next state’s feature encoding will lead to more exploration of that region of the environment. Moreover, parts of the environment that are completely unpredictable and unaffected by the actions will have no incentive in being encoded by the ICM. The model should therefore “distill” the current state to only its essential parts.
Results are impressive, especially in the sparse and very sparse reward settings (see paper for details) where the model still learn significantly better policies than other methods in terms of extrinsic reward.
DONE Comments
Comment on generalization in RL from the paper:
It is common practice to evaluate reinforcement learning approaches in the same environment that was used for training. However, we feel that it is also important to evaluate on a separate “testing set” as well. This allows us to gauge how much of what has been learned is specific to the training environment (i.e. memorized), and how much might constitute “generalizable skills” that could be applied to new settings.
I think this research direction is extremely interesting. No/sparse-reward RL seems like a promising approach to construct agents that can efficiently explore and reach good performance on unseen environments.
The authors recognize a few issues with their method, but the overall principle seems solid. However, the component that still bothers me is the fact that the ICM, policy, etc. still rely on neural networks trained with gradient descent. This is in my opinion why they won’t really be able to do much more than what they’ve been trained to do and still suffer from the usual issues with neural networks. They won’t be able to learn things on the long term or re-use successful components or innovate significantly.
This issue with neural networks and gradient-based learning is illustrated in the paper by the following quote:
In Mario our agent crosses more than 30% of Level-1 without any rewards from the game. One reason why our agent is unable to go beyond this limit is the presence of a pit at 38% of the game that requires a very specific sequence of 15-20 key presses in order to jump across it. If the agent is unable to execute this sequence, it falls in the pit and dies, receiving no further rewards from the environment. Therefore it receives no gradient information indicating that there is a world beyond the pit that could potentially be explored.
Bibliography
- Deepak Pathak, Pulkit Agrawal, Alexei A. Efros, Trevor Darrell. . "Curiosity-Driven Exploration by Self-Supervised Prediction". In 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 488–89. IEEE. DOI.
Loading comments...