Projects
A selected list of my projects. Some were done as part of a university course and others as side-projects.

Open-ended creation of hybrid creatures with Neural Cellular Automata
Submission to the Minecraft Open-Endedness Challenge 2021.

Stochastic optimization for large scale optimal transport
A university project about Stochastic Optimal Transport.
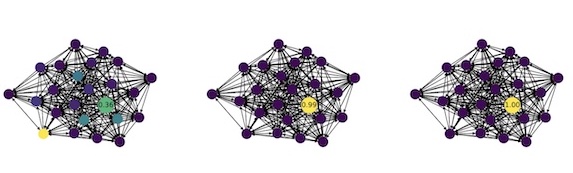
Graph neural networks for influence maximization
A project about graph neural networks for influence maximization in graphs.

Adversarial examples in reinforcement learning
A small review of existing adversarial methods in RL.

Parliament
A data platform for French parliamentary data with ingestion, enrichment, and API serving.
Bring Your Laptop
A PWA for finding work-friendly cafes in Paris, with crowd-sourced reports and maps.
EasyRoute
A route planning API that generates personalized walking and biking routes with points of interest.
HatchForge
A raymarching renderer that produces SVG files with hatching lines, inspired by engraving aesthetics.
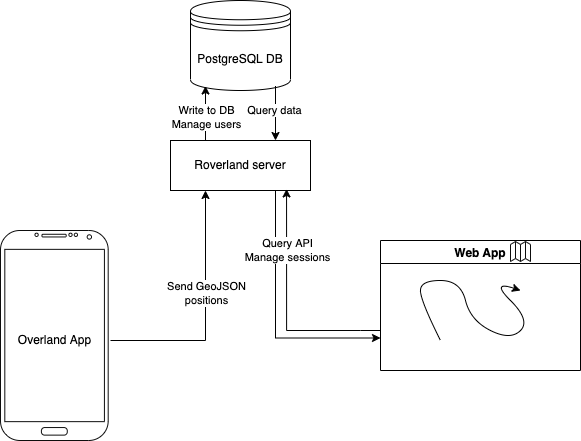
Roverland location tracking server
Building a self-hosted location tracking server in Rust

Asymmetric numeral systems in Rust
Building a fast entropy coder in Rust.

Posos Challenge
My work on the Posos sentence classification challenge.

Style transfer with generative adversarial neural networks
A project about applying style transfer with GANs.
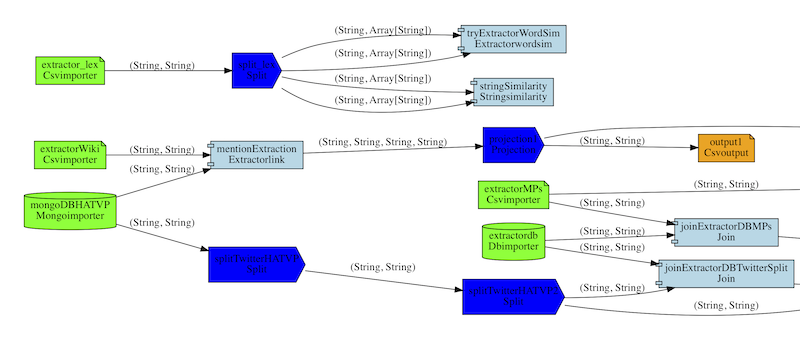
Data journalism extractor
A large-scale data exploration tool for data journalism.
Arxiv explorer
A small web app project for exploring Arxiv papers.