- tags
- Neural networks
- source
- (Greydanus 2020)
DONE Summary
This paper introduces a minimalist 1D version of the MNIST dataset for studying some basic properties of neural networks. The authors simplify the MNIST dataset by assigning a 1D glyph to each digit. These glyphs are padded, translated, sheared and blurred to build a dataset of multiple different objects.
The figure from the paper shown below illustrates this dataset’s construction:
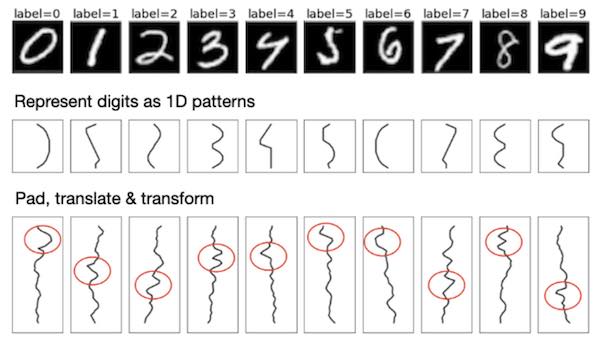
Figure 1: 1D simple MNIST
This dataset is shown to be a suitable tool to study very small neural networks and their properties. The authors discuss:
- Lottery tickets
- Double descent
- Metalearning
- The use of strong spatial priors such as translation invariance
- Pooling methods
DONE Comments
This is an interesting paper, which for once isn’t about getting bigger models or better results than the state of the art. The small MNIST dataset may lead to interesting insights into the functioning of neural networks but I’m not sure that will be enough for solving the big questions about deep learning. The secrets of those huge recent models might elude us for a while simply because we don’t have the resources (mathematical or computational) to study them.
Bibliography
- Sam Greydanus. . "Scaling *down* Deep Learning". http://arxiv.org/abs/2011.14439.
Loading comments...